Introduction
Client is a large telco provider. Client has a mission-critical application called “SecureNetAccess”, hereby referred as “SNA” is the method of extending the telco customer’s network to its (customer’s customer) premise using the telco customer’s own facility and /or third party facility. SNA provides access optimization and related services for LD and local orders in all segments and networks of the domestic US company. It additionally calculates least costs for each access possibility using Industry Tariff information (from CCMI Inc via StarPlus) as well as internal pricing data and algorithms and company-defined surcharges.
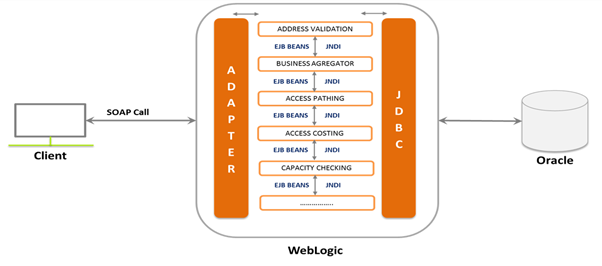
The application has been developed more than a Decade ago using EJB 3.0. The Legacy architecture, application is hosted on 8 WebLogic instances and 4 Servers. The application has 200+ batch jobs that are scheduled on on-demand, hourly, daily, weekly and monthly basis. The critical component of the application are the batch jobs and the Oracle DB that they update on a frequent basis. The reports generated by the batch jobs are utilized by downstream systems for mission-critical activities.
The application was ear marked by the customer to be migrated to AWS. Customer has a Data center exit plan and has decided to migrate the applications from on premise to the cloud. Specifically, SNA on cloud would benefit in terms of on demand scaling of batch jobs and improvement of performance.
Current System overview:
200 batch jobs to be executed per month with
- 20% on-demand ETL Jobs
- 40% Reporting and analytics jobs with a daily/weekly/monthly schedule
- 20% Report jobs that are on-demand
- 20% combination of ETL and Report Jobs
The project had the components as part of the batch jobs
- Batch Jobs:
a. Batch jobs driven by UI. Example: user uploads csv of records to validate addresses. This gets executed as an user triggered batch jobs
b. ETL Loads: Convert files (CSV, Logs, XLS, XLSX) and store to backend DB
c. Maintenance Batches: Performs DB Maintenance: Purges and Deletes
d. Reporting Batches: Generate Reports. Feed Reports to external systems
2) Batch Job Details:
a. Currently batch jobs run as shell scripts and scheduled by Cron. Visibility is available only for UI scheduled Jobs and not for the cron scheduled daily, weekly and monthly batch jobs. The backend (cron driven) batch jobs do not have management dashboard level visibility. Need a unification and standardization of all jobs when in AWS
b. Currently all Jobs are scheduled by CRON and written in shell scripts. This is much unstructured. There needs to be a standardization of Batch Jobs. Improve security by creating service accounts. Masking passwords in shell scripts etc
c. For ETL Jobs we need to have a ETL tool which will parallelize the nodes on VM.
d. Scalability: We need to provide a batch ecosystem that is scalable. Currently the batch job in production has limitations. Some of the CSV Uploads prevent a file with more than 5000 records to be uploaded at the same time
Migration Design Considerations
- A Scalable ETL model for converting CSV, batch files to EC2 based batch scripts scheduled using cloud watch scheduler. There were severe performance bottlenecks in doing the same limiting the number of records that was processed.
- The architecture was required to be divided into master node and multiple read replicas. Processes/Jobs that need all CRUD or mixed crud operations could talk to master nodes. Changes need to be done in the code for the DB connection string to point to the master. We need to divide the reporting and analytics batch jobs to point to read replicas.
Scope of Work
SNA Batch Jobs
- Discovery and analysis of all Batch Jobs with a goal to run the same with AWS RDS Oracle
- Batch jobs and anonymous SQL files compatible with AWS RDS Oracle
- Test 254 Batch Jobs after migration
- Create and integrate the changes in CI/CD Pipeline
- CI-CD Pipeline constitutes spin up of environment (EC2) to host the batch
- RDS DB is assumed to have been already provisioned and made available by the Customer team and hence not included in CI-CD
- QA (Dev [Unit Test] – Dev Team, SIT – Newt QA, and Staging – Customer QA) (These are technical tests not functional tests)
- Defect fixing during QA
DB & PLSQL Objects
- Discovery and analysis of all UTLs in SNA DB PLSQL objects in order to make them compatible with AWS RDS Oracle
- These include: UTL_FILE, UTL_SMTP, SFTP, SCP, UTL_TCP
- Scripts needing elevated and special privileges
- Oracle options compatible/not compatible with AWS RDS Oracle
- Change the scripts and make them compatible with AWS RDS Oracle
- Create and integrate the changes in CICD Pipeline
- CI-CD is restricted up to build automation
- All instances spin-up should be automated
- Deployment and configuration of RDS is excluded
- QA (Dev [Unit Test] – Dev Team, SIT – Newt QA, and Staging – QA) ((These are technical tests not functional tests)
- Defect fixing during QA
Solution approach
- Just about refactor the batch jobs to function for RDS with an otherwise lift and shift approach
- Alternatives to the RDS incompatible elements will be refactored with an otherwise lift and shift approach
- UTL_FILE package is being used to write to file on the RDS instance, Prerequisite is to have the custom directories created and the necessary privileges we tested the functionality by creating custom directories on RDS and also read/written files on the RDS directory objects which are now vetted by DBA’s so we need not to refactor the code with UTL_FILE being used.
- SFTP and SCP will be refactored as Java code callable from Shell scripts.
| Sl. No. | Method | Approach under RDS | Known Restrictions | Remarks |
| 1 | UTL_FILE | using “rdsadmin.rdsadmin_util.create_directory” utility, create a new directory tagged to a specific alias directory name.
utilize utl_file functionality to match and work on par with the existing source code and ensure all the functional components is being covered.
|
Creation of sub folders not possible
|
|
| 2 | UTL_SMTP |
|
|
https://aws.amazon.com/about-aws/whats-new/2016/12/amazon-rds-for-oracle-now-supports-outbound-network-access/ |
| 3 | UTL_TCP |
|
|
https://aws.amazon.com/about-aws/whats-new/2016/12/amazon-rds-for-oracle-now-supports-outbound-network-access/ |
| 4 | SFTP |
|
|
|
| 5 | UTL_MAIL |
|
|
for outbound mail |
Deployment Architecture
The newly developed add in is deployed in AWS. The systems architecture is a under:
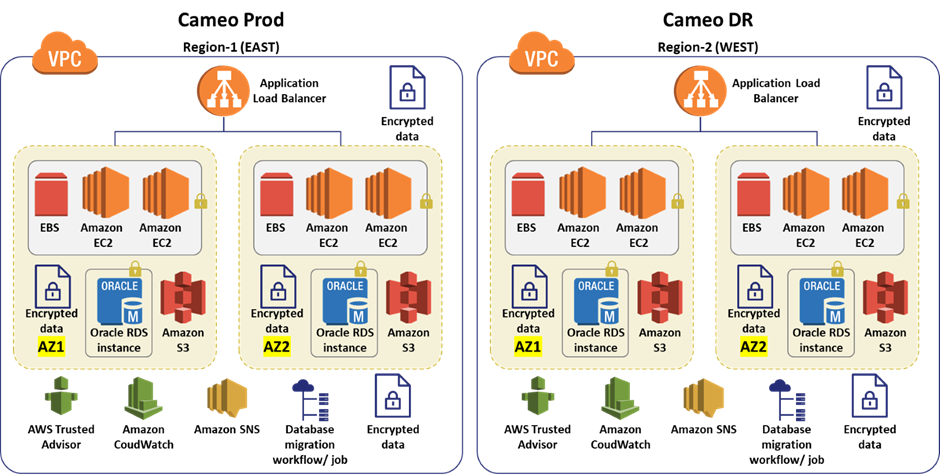
AWS services used:
The AWS services used were: EBS, EC2, S3, Cloud Watch, EBS, SNS, ALB, VPC and RDS Oracle
Third-Party Services used:
The application used Java, Spring REST service, Spring Microservices, Tomcat, Oracle/Aurora, Swagger, Maven, sl4j, Junit, Bootstrap, JIRA, Stash
Security considerations and implementation
AWS Key Management Service (AWS KMS) is used to store all the key’s as secured
- Data At rest and In-Transit are encrypted using Transport Layer Security 1.2 (TLS) with an industry-standard AES-256.
- We are triggering an email for success and failure record’s to the admin
Business benefits of the migration:
➢ 200K Batch jobs processed in a month
- Up to 20 complex ETL processed a day
- 58+ Modules migrated end to end
- 7 Data sources of each above 6TB consolidated
- Integrated all modules to the DevOps pipeline