
As much as we see the prevalence of Jenkins for CI/CD, the mission critical nature of build and deploy processes is emerging faster. This post talks about the need and how-to create a Jenkins Master Server High Availability environment and implement a recoverability feature from the current failed or stopped job in a secondary site in a Disaster Recovery scenario. Currently this is not available in Open source Jenkins.
Need for Jenkins Master Server High Availability and Job resume from current state than from start
- On day to day basis, Jenkins Master Server is used for triggering multiple parallel jobs which will enable the job to run in slave (Node) based on the node availability which is maintained in the queue. What happens if the Master Server is down when your multiple job which is running for days or hours (i.e. DB backup jobs etc)
- Once your Master Jenkins Server is up, you might have to re run the job from first step which is tedious and time consuming
- Once your Master Jenkins Server is up, Current Job which was running before the Jenkins server was down should be restarted as Jenkins will not recognize past running status after restarting Jenkins Master server in case DR situation
- You might need the job to be resumed from current failed or stopped state during DR situation which this whitepaper has the POC which can help to resume the Pipeline job in case of DR situation
- Need for Jenkins Master HA and Job resume is purely organizational decision based on no of multiple jobs and jobs running for hours and days for any maintenance activity
- Also based on the criticality to resume from failed state rather than from first step
Based on above scenarios mentioned in summary section we propose Jenkins Master HA Setup using shared NFS and the combination of job resuming from pipeline job from the current failed state
We will talk about two parts in solution
- Jenkins Master HA setup using HA Proxy
- Engineering Pipeline Job Resuming from current failed state after Step 1 is completed
Jenkins Master HA Architecture Diagram
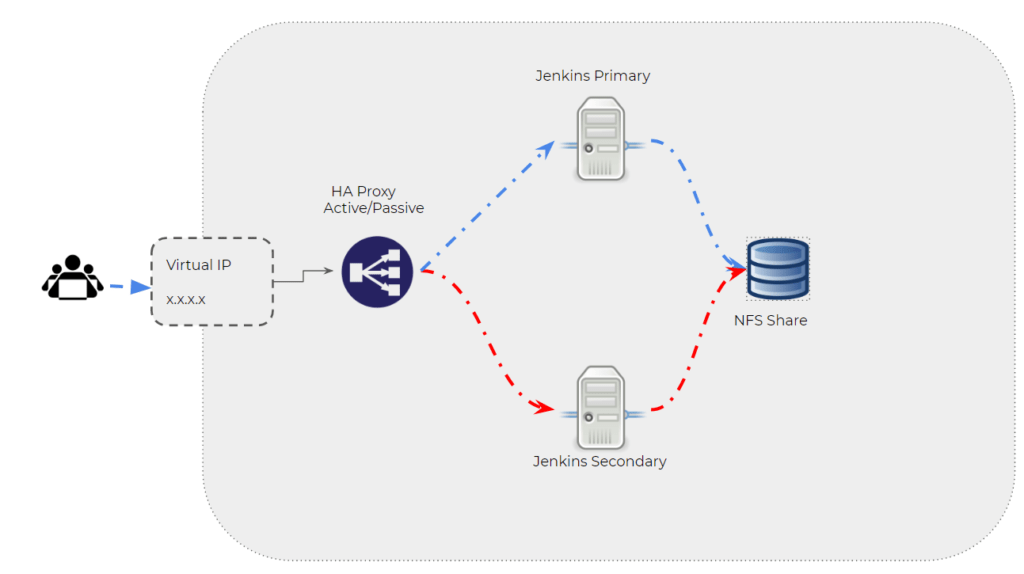
Pre-Requisites
- Jenkins Master Primary Server setup
- Jenkins Master Secondary Server setup
- HA Proxy or any other Load Balancer
- Shared NFS which can be accessible by both Jenkins Primary and Secondary Server
- Jenkins Masker setup Jar file which will be used for installing Master
Implementation
Jenkins Master HA Setup
- Create a Shared NFS or Mount it in the Primary or secondary Server
- Run the Jenkins Setup Jar file with options to point the shared NFS Folder as $JENKINS_HOME in Primary Server
- Repeat the same step for secondary server as well
- Now, both primary and secondary server will read the same configuration files
- Configure your Active Passive HA setup for Jenkins Server with your Jenkins Master Primary server as active and Secondary Master Server as Passive
Engineering Pipeline Job Resuming from current failed state (Newt Global IP)
- Once Jenkins Master HA is completed, you need to configure the pipeline job to resume from current failed state to trigger the job
- This feature was available in Jenkins Enterprise edition but not in open source
- We from Newt global have engineered this feature in open source Jenkins which will have
- Button to resume the Pipeline job which was failed or stopped to run within 2 hours from failed state
- This feature will be useful for organization running major database backup jobs configured in Jenkins
- During DR, HA proxy will point to Secondary Jenkins Master Server
- During that time, any pipeline Job triggered in master should have stopped even though node or slave is the place where the job is running
- Since we have the feature engineered form Newt global for pipeline job
- Once secondary server is up and running, pipeline job will have button to resume from current failed status and not from start
This solution is beneficial to organization running multiple parallel jobs and jobs that take a long time to complete. This feature can be implemented on a case to case basis, to reduce time to market and avoid build time due to rework or restart from start in these situations.
ABOUT THE AUTHOR
MADHAN RAMAKRISHNAN PMP ,PMI ACP
Director -Devops Practice/Program, Newt Global